What is Jaro-Winkler Similarity?
Jaro-Winkler similarity is a way of measuring how similar two strings are. It is fairly easy to understand and quick to implement.
Why should I care?
String similarity metrics have various uses; from user-facing search functionality to spell checkers.
There are a few common string similarity metrics. Knowing a little about each will help you to choose the right one, should you ever need to implement something like this yourself.
Jaro Similarity, and the modified version - Jaro-Winkler - are two common ones.
In 5 minutes or less:
Imagine we're building the search functionality for an app store.
If a user misspells their search, we'd like to be able to suggest the app we think they were looking for.
For example; the user is searching for the 2009 viral hit farmville, but badly mistypes it as:
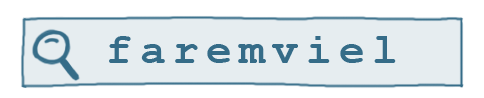
If we could compare this search string to all of the titles in our app store, we could show the user the apps that most closely match what they typed.
This is where the Jaro Similarity metric comes in...
Jaro Similarity
Let's calculate the similarity between the user's search string and the correct app title:

Created by Matthew A. Jaro in 1989, the Jaro Similarity metric compares two strings and gives us a score that represents how similar they are.
The result is a number between 0 and 1, where 0 means the strings are completely different and 1 means they match exactly.
The first step to calculating the Jaro similarity is to count the characters that match between the two strings.
But, to be considered a 'match', the characters do not need to be in the same place in both strings - they just need to be near to each other.
This accounts for the common typing mistake where you accidentally enter some characters in the wrong order.
How near those characters need to be before we consider them a match is calculated as follows:

Both of our strings are 9 characters long. That gives us a result of 3.
That means that any two characters in our strings 'match' if they are either:
- In the same place in both strings
- No further than
3characters away from each other
Here's what it looks like if we draw these matches:
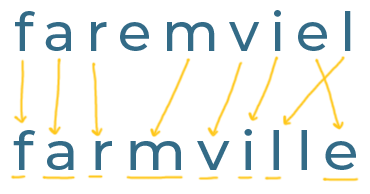
If there were no matches, we wouldn't need to go any further - the Jaro Similarity would simply be 0.
We have 8 matching characters though, so the next step is to calculate the number of 'transpositions'.
Transpositions are the characters that match, but are in the wrong order. We count them, and then we half that number.
Our strings have 2 matching characters that are in a different order (the final e and l are backwards in the user's search term).
Halving this gives us 1 'transposition'.
Now all we have to do is plug these numbers into the following formula
(we use the term simj to mean 'Jaro Similarity' - the thing we're calculating):
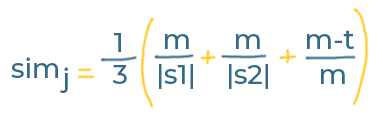
This looks complex, but we really only need a few values:
|S1|and|S2|are the lengths of the two strings we are comparing (ours are both9characters long)mis the number of matches - we have8tis the number of 'transpositions' - we have1
Given those values, this is the Jaro Similarity for faremviel vs farmville:
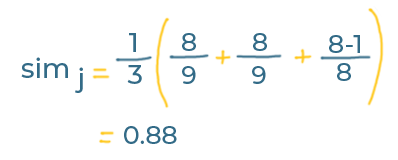
Our strings have a similarity of 0.88, which means that they are very similar.
If we calculate the Jaro Similarity of the user's search term against other games in our app store, it becomes clear what the user was intending to search for:
- 'faremviel' vs 'farmville':
0.88 - 'faremviel' vs 'farmville 2':
0.83 - 'faremviel' vs 'clash of clans':
0.46 - 'faremviel' vs 'minecraft':
0.31
Jaro-Winkler Similarity
This modification of Jaro Similarity was proposed in 1990 by William E. Winkler.
The 'Jaro-Winkler' metric takes the Jaro Similarity above, and increases the score if the characters at the start of both strings are the same.
In other words, Jaro-Winkler favours two strings that have the same beginning.
This is the formula for the 'Jaro-Winkler Similarity':
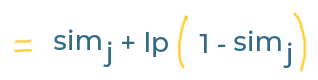
We need the following values to use it:
simjis the Jaro Similarity of our comparison above (0.88)lis the number of characters that are the same at the start of both strings (up to a maximum of 4). Our strings both start withfar, so we use a value of3for this.pis the 'scaling factor'.0.1is usually used.
This is the Jaro-Winkler calculation for faremviel vs farmville:
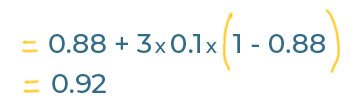
Two strings with no matching characters at the start would keep the same score, but because our
strings have letters in common at the beginning, this version of the metric has boosted our score
from 0.88 up to 0.92.
Whether Jaro or Jaro-Winkler is the right choice depends on your specific use case. Try both (and other string similarity algorithms), and see what works best for your data.
Want to know more?
Check out these links:
