What is Huffman Coding?
The Huffman Coding algorithm is a building block of many compression algorithms, such as DEFLATE - which is used by the PNG image format and GZIP.
Why should I care?
Have you ever wanted to know:
- How do we compress something, without losing any data?
- Why do some things compress better than others?
- How does GZIP work?
In 5 minutes or less:
Suppose we want to compress a string (Huffman coding can be used with any data, but strings makes good examples).
Inevitably, some characters will appear more often than others in the text to be compressed. Huffman Coding takes advantage of that fact, and encodes the text so that the most used characters take up less space than the less common ones.
Encoding a string
Let's use Huffman Encoding to compress a (partial) quote from Yoda; "do or do not".

"do or do not" is 12 characters long. It has a few duplicate characters, so it should compress quite nicely.
For the sake of argument, we'll assume that storing each character takes 8 bits (Character Encoding is another topic entirely). This sentence would cost us 96 bits, but we can do better with Huffman coding!
We begin by building a tree structure. The most common characters in our data will be closer to the root of the tree, while the nodes furthest away from the root represent the less common characters.
Here's the Huffman Tree for the string "do or do not":
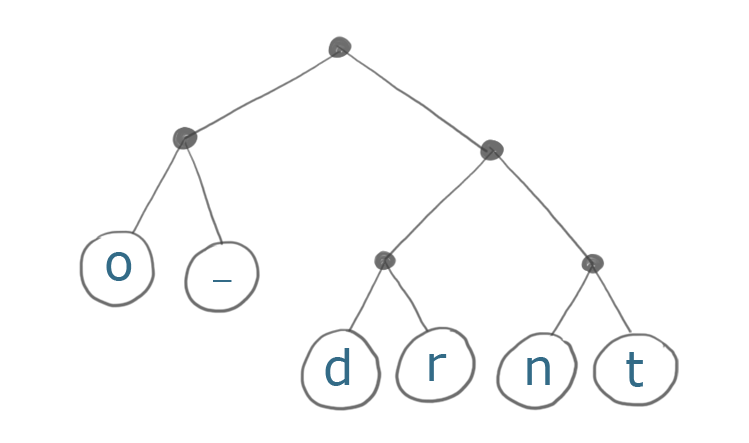
The most common characters in our string are 'o's (4 occurrences) and spaces (3 occurrences). Notice that the path to those characters is only two steps away from the root, compared to three for the least common character ('t').
Now, instead of storing the character itself, we can store the path to the character instead.
We start at the root node and work our way down the tree towards the character we want to encode. We'll store a 0 if we take the left-hand path, and a 1 if we take the right.
Here's how we would encode the first character, d, using this tree:
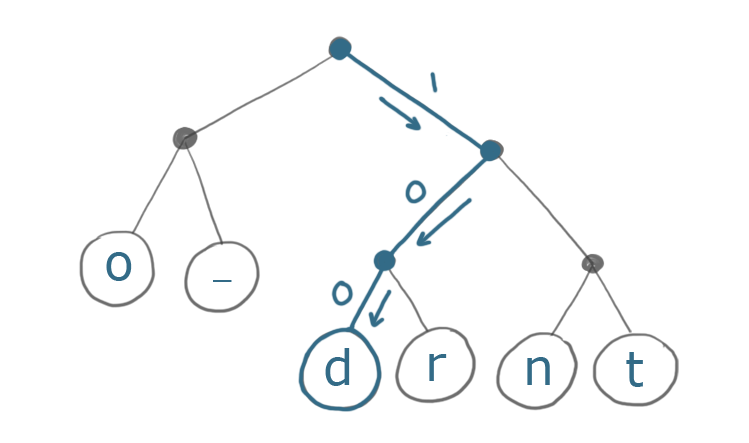
The end result is 1 0 0 - 3 bits instead of 8. That's quite an improvement!
The entire encoded string looks like this:

This is 29 bits instead of 96, with no data loss. Great!
Decoding our string
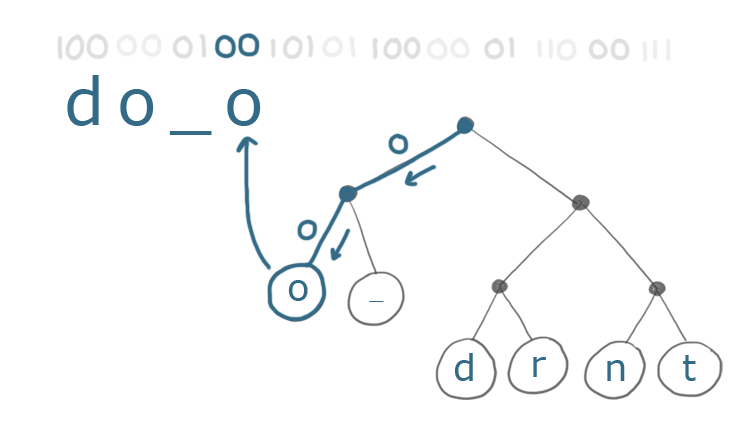
To decode our text, we simply follow each 0 (left branch) or 1 (right branch) until we reach a character. We write that character down, and then start again from the top:
Sending the encoded text
But wait.. when we send the encoded text to somebody else, don't they need the tree too? Yes! The other side needs the same Huffman tree in order to decode the text correctly.
The simplest, but least efficient way, is to simply send the tree along with the compressed text.
We could also agree on a tree first, and both use that tree when encoding or decoding any string. That works OK when we can predict the distribution of characters ahead of time, and could build a relatively efficient tree without seeing the specific thing we're encoding first (as we could with English text, for example).
Another option is to send just enough information to allow the other side to build the same tree as us (this is how GZIP works). We could send the total number of times that each character occurs, for example. We have to be careful though; there is more than one possible Huffman tree for the same block of text, so we have to make sure we both construct the tree in exactly the same way.
Want to know more?
Check out these links:
