What is CAP Theorem?
CAP Theorem describes the decisions we have to make when building a distributed data store.
Why should I care?
Have you ever wanted to know:
- How distributed databases handle network failures?
- What tradeoffs we must make when designing distributed data stores?
In 5 minutes or less
Eric Brewer's CAP Theorem tells us that a distributed data store must choose no more than two of the following:
- Consistency
- Availability
- Partition Tolerance.
What do those definitions mean, and why can't we have all three?
Let's imagine we're designing a distributed database.
For simplicity our database will have just two interconnected instances, or 'nodes':

Partition Tolerance
Partition Tolerance means that one or more nodes in our distributed system can be split up and unable to communicate with each other (partitioned), and the system can still function.
Only a complete network failure is allowed to cause the system to respond incorrectly, anything else must be tolerated.
If we have a single node then there can be no partitions. But, in a distributed system, faults are inevitable given enough time. Therefore we cannot sacrifice Partition Tolerance.
With that in mind, we can actually re-state the problem like this:
In the event of a Partition, should we choose either Consistency or Availability?
Imagine there's a fault in our system, and the connection to one of the nodes is broken. Our distributed database is now partitioned.

Somebody tries to update a record on one of the nodes.. What do we do now?
Choosing Consistency
'Consistency' in CAP Theorem means that I can update a record on one node, and somebody reading from another node will immediately see the effect of my update.
(Note: this is specifically called 'linearizable consistency').
Obviously, instant communication isn't realistic in a distributed environment, so in practice, the goal is to reduce this to a level where we don't notice it.
This is a really useful property if you are a banking system. It would be a big problem if I could withdraw money from one ATM, then walk down the road to another ATM and withdraw the same amount again, because the database was not consistent across all nodes.
The nodes in our example database can no longer communicate, so we cannot reflect a change across all nodes 'instantly'.
So, if we want to make sure both nodes stay 'consistent', there are a few ways to handle this. We could shut down entirely, or refuse all updates and only allow reads, for example.
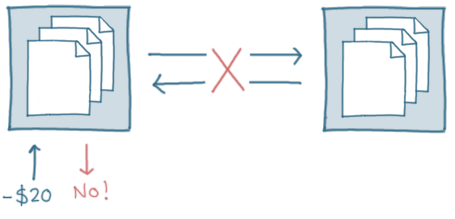
Because we can't accept the update request though, we are sacrificing availability...
Choosing Availability
'Availability' means that if we make a request to any working node, we must get a non-error response, regardless of any partitions in the system.
The data is allowed to be out of date, or 'stale', but it must be available.
Twitter is a good example of a system where we might choose Availability. If I 'like' a tweet, but the other nodes don't reflect that 'like' immediately, it's really not the end of the world.
In this case, it's more important for the system to be 'available' and accept the update than to be 'consistent'.
In our example scenario, we could continue to allow clients to read and write to nodes on both sides of the partition:
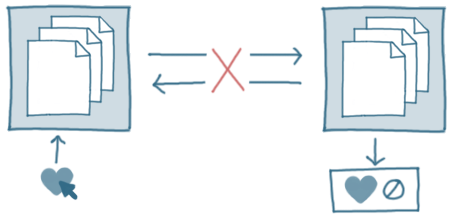
That would give us a system that is Available, but because there's no way for those nodes to keep their information in sync while partitioned, it's impossible for this to be (immediately) Consistent too.
This problem is the root of CAP Theorem. We cannot have both Consistency and Availability in the event of a partition (a loss of communication between nodes).. we must choose between the two.
Want to know more?
Check out these links:
